
This is the first of two tutorials on monitoring machine metrics of your device fleet with Prometheus.io.

Prometheus is a tool, initially built by soundcloud to monitor their servers, it is now open-source and completely community driven. It works by scraping “targets” which are endpoints that post key-attribute machine parseable data. Prometheus then stores each scrape as a frame in a time series database allowing you to query the database to execute graphs and other functions like alerts.
tl;dr This post runs through the configuration required to get prometheus.io running on a fleet of balena devices. Skip ahead if you’d like to go straight to deploying and running the demo.
Collecting
The first task is collecting the data we’d like to monitor and report it to a URL reachable by the Prometheus server. This is done by pluggable components which Prometheus calls exporters. We’re going to use a common exporter called the node_exporter which gathers Linux system stats like CPU, memory and disk usage. Here is a full list of the stats the node_exporter collects.
Once the exporter is running it’ll host the parseable data on port 9100, this is configurable by passing the flag -web.listen-address ":<PORT>" when spawning the exporter.
Once running visit https://<your-device-ip>:9100/metrics, you’ll see all the machine metrics from the node_exporter in plain-text.
Scraping
We now need to make sense of the data being collected that’s where the Prometheus server comes in. prometheus.yml holds the configuration that tells Prometheus how and which exporters to scrape. Let’s go run through it and explain the configurations.
The scrape_interval is the interval that Prometheus will scrape it’s targets which are exporter endpoints. This will control the granularity of the time-series database. We have set it to scrape every 5s this is for demo purposes, usually, you’d use something like the 60s.
global:
scrape_interval: "5s"
Rule files specify a list of files from which rules are read, these rules and trigger webhooks to set alerts more on that a little later.
rule_files:
- 'alert.rules'
The scrape_configs allow you to set targets for each scrape job. We will give it a job_name composed of the exporter name and a trimmed version of the RESIN_DEVICE_UUID we then add target endpoints which is the node_exporter server we mentioned in the previous section. Then we add some balena specific labels to make identifying the target easier.
scrape_configs:
- job_name: "node"
static_configs:
- targets:
- "localhost:9100"
labels:
resin_app: RESIN_APP_ID
resin_device_uuid: RESIN_DEVICE_UUID
These labels are replaced at runtime with real values from balena environment using the config.sh.
Once the Prometheus server is running, activate and visit the device’s public URL.
On the prometheus dashboard, there won’t be much to start let’s add a graph. Select add graph and add 100 * (1 - avg by(instance)(irate(node_cpu{job='node',mode='idle'}[5m]))) to the expression input. This query will find the average % CPU between the last two data points going back as far as 5 minutes, if no data point before that exists. Now we are able to query scraped data, great!
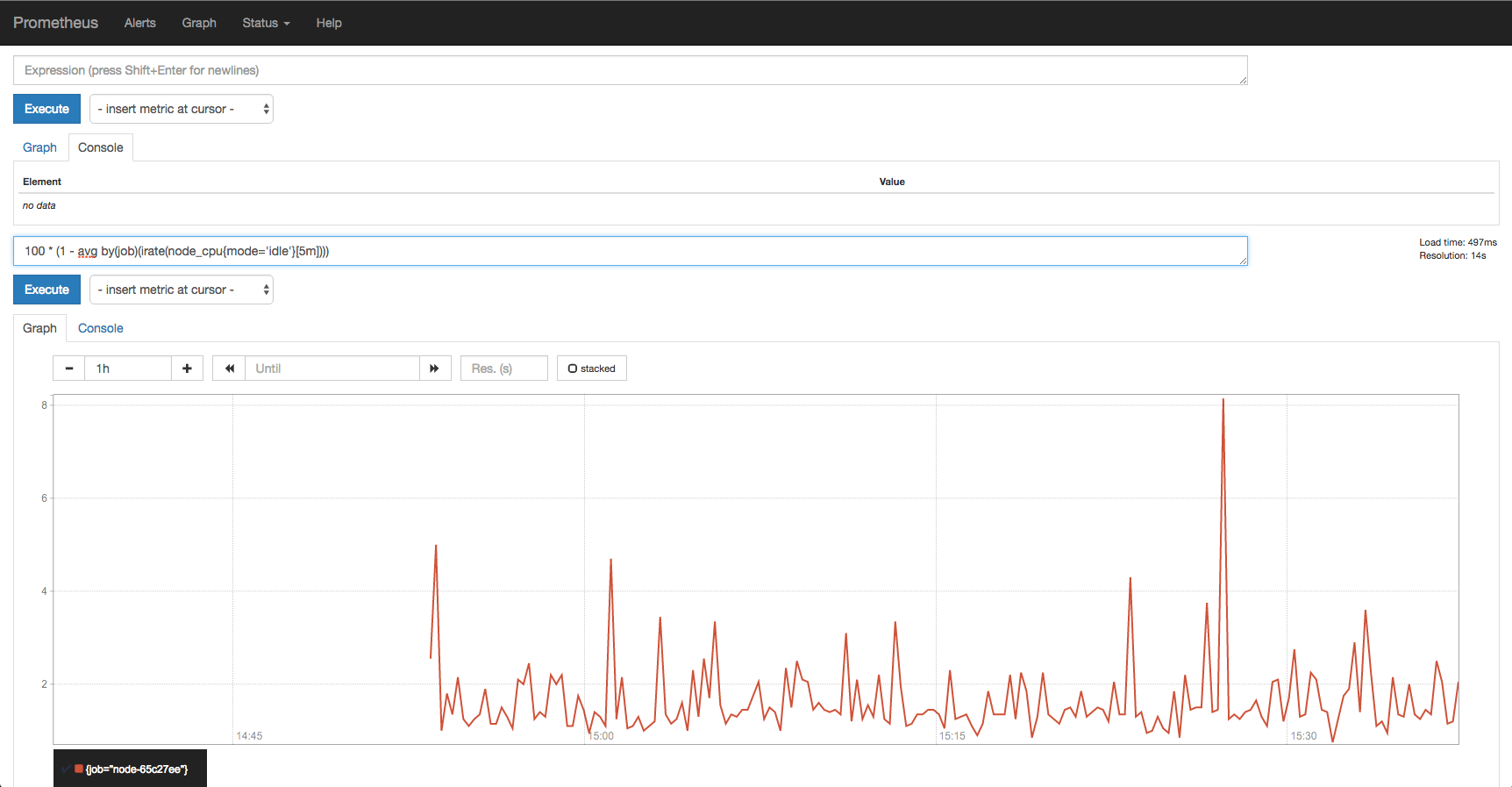
Prometheus also comes with a pre-configured console for node_exporter jobs to view this visiting https://<your-device-url>/consoles/node.html. Voila!
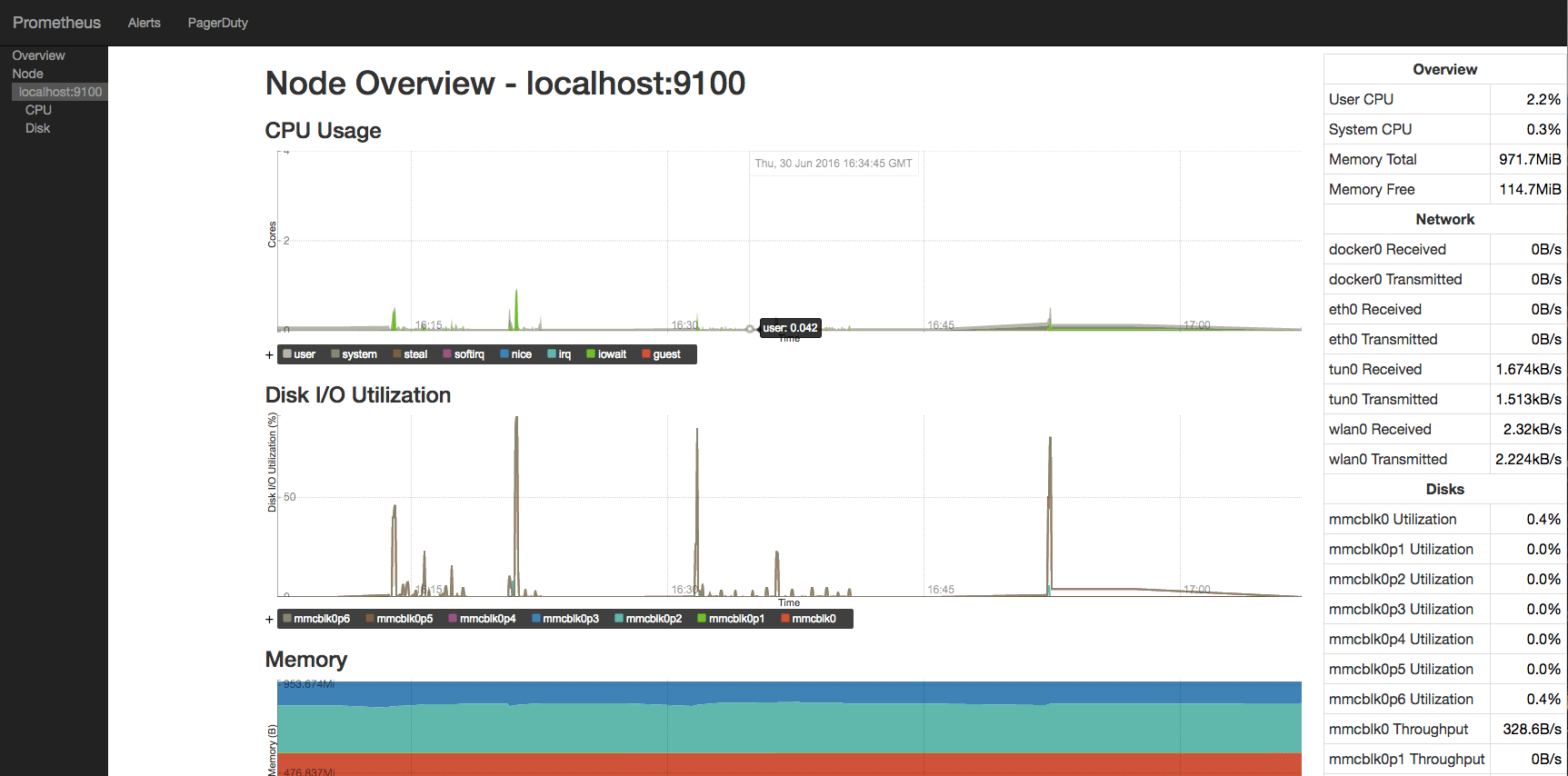
Alerts
So now we have a way to collect data as well as query that data. Let’s set up some alerts, these will query the scraped instances and send us an email if those queries evaluate to an undesirable value.
The alerting is handled by a separate component, the alertmanager.
The first thing to do is create some rules that Prometheus can check after each scrape. We have defined several rules in alert.rules to get you started, let’s take a look at one of them.
ALERT cpu_threshold_exceeded
IF (100 * (1 - avg by(job)(irate(node_cpu{mode='idle'}[5m])))) > THRESHOLD_CPU
ANNOTATIONS {
summary = "Instance {{ $labels.instance }} CPU usage is dangerously high",
description = "This device's CPU usage has exceeded the threshold with a value of {{ $value }}.",
}
Here we define the alert and pass it the query we mentioned earlier as an if statement. If the statement finds that the value exceeds our THRESHOLD_CPU it will trigger the alert. We have also added ANNOTATIONS to make the alert more descriptive.
We then need to configure the Alertmanager to handle the actions required when an alert is fired. The configuration can be found in alertmanager.yml. The Alertmanager isn’t a full SMTP server itself, however it can pass on emails to something like Gmail which can send them on our behalf.
route:
group_by: [Alertname]
# Send all notifications to me.
receiver: email-me
# When a new group of alerts is created by an incoming alert, wait at
# least 'group_wait' to send the initial notification.
# This way ensures that you get multiple alerts for the same group that start
# firing shortly after another are batched together on the first
# notification.
group_wait: 30s
When the first notification was sent, wait 'group_interval' to send a batch
of new alerts that started firing for that group.
group_interval: 5m
If an alert has successfully been sent, wait 'repeat_interval' to
resend them.
repeat_interval: 3h
templates:
'/etc/ALERTMANAGER_PATH/default.tmpl'
receivers:
name: email-me
email_configs:
to: GMAIL_ACCOUNT
from: GMAIL_ACCOUNT
smarthost: smtp.gmail.com:587
html: '{{ template "email.default.html" . }}'
auth_username: "GMAIL_ACCOUNT"
auth_identity: "GMAIL_ACCOUNT"
auth_password: "GMAIL_AUTH_TOKEN"
Here we catch all alerts and send the to the receiver email-me.
Take note of templates: - '/etc/ALERTMANAGER_PATH/default.tmpl' This overrides the default templates used for notifications with our own which you can see in default.tmpl.
Testing the alerts
Visit https://<your-device-url>/alerts, you’ll see a couple alerts we defined earlier in alert.rules The easiest one to test is the first, service_down, this alert is triggered when the targets (the instances prometheus server is scraping) drops to zero. Because we only have one target instance (node_exporter) we may simply kill that process to trigger the alert.
Using the web terminal run $ pkill node_exporter. If you then refresh https://<your-device-url>/alerts you’ll see the alert is firing. You will also get an email with the alert description and which device it is affecting.

Running the demo
Find the code here.
- Provision you’re device(s) with balena
git clone https://github.com/balena-io-playground/balena-prometheus && cd balena-prometheusgit add remote balena <your-resin-app-endpoint>git push balena master- Add the following variables as Application-wide environment variables
| Key | Value | Default | Required |
|---|---|---|---|
| GMAIL_ACCOUNT | your Gmail email | * | |
| GMAIL_AUTH_TOKEN | you Gmail password or auth token | * | |
| THRESHOLD_CPU | max % of CPU in use | 50 | |
| THRESHOLD_FS | min % of filesystem available | 50 | |
| THRESHOLD_MEM | min MB of mem available | 800 | |
| LOCAL_STORAGE_RETENTION | Period of data retention | 360h0m0s |
Coming up
This demo provides some basic fleet monitoring, but there it doesn’t provide a complete view of your entire fleets statistics in a single dashboard. In the next post we’ll connect all the devices to a central grafana dashboard for fleet-wide, as well as a device-specific views – stay tuned!
Any questions? – ask us on gitter!